



数控机床热误差补偿模型稳健性比较分析
2017-12-27 来源: 合肥工业大学仪器科学与光电工程学院 作者: 苗恩铭 龚亚运 徐祗尚 周小帅
摘要:数学模型的精度特性和稳健性特性对数控机床热误差补偿技术在实际中的实施性影响不容忽视。对数控加工中心关键点的温度和主轴z 向的热变形量采用多种算法建立了预测模型,对不同算法拟合精度进行分析。同时进行全年热误差跟踪试验,获得了机床在不同环境温度和不同主轴转速的试验条件下的敏感点温度和热误差值。以此为基础,对各种预测模型的预测精度进行比较验证不同模型的稳健性。结果表明,多元线性回归算法的最小一乘、最小二乘估计模型以及分布滞后模型在改变试验条件时预测精度下降,而基于支持向量回归机原理的热误差补偿模型仍能保持较好的预测精度,稳健性强。这为数控机床热误差补偿模型的选择提供了具有实用价值的参考,具有很好工程应用性。
关键词:数控机床;热误差;稳健性;多元线性回归模型;分布滞后模型;支持向量回归机
0 前言
在数控机床的各种误差源中,热误差已经成为影响零件加工精度主要误差来源[1]。减少热误差是提高数控机床加工精度的关键。在热误差补偿中,建模技术则是重点。由于机床热误差在很大程度上取决于加工条件、加工周期、切削液的使用以及周围环境等等多种因素,而且热误差呈现非线性及交互作用,所以仅用理论分析来精确建立热误差数学模型是相当困难的[2]。最为常用的热误差建模方法为试验建模法,即根据统计理论对热误差数据和机床温度值作相关分析。杨建国等[3-5]提出了数控机床热误差分组优化建模,根据温度变量之间的相关性对温度变量进行分组,再与热误差进行排列组合逐一比较选出温度敏感点用于回归建模。韩国的KIM等[6]运用有限元法建立了机床滚珠丝杠系统的温度
场。
密执安大学的YANG 等[7]运用小脑模型连接控制器神经网络建立了机床热误差模型。ZENG 等[8]用粗糙集人工神经网络对数控机床热误差分析与建模,并对建模精度进行了论证。CHEN 等[9]运用聚类分析理论和逐步回归选择三坐标测量机热误差温度敏感点,用PT100 测量温度、激光干涉仪测量三坐标测量机热误差,建立了多元线性模型。由于这些建模方式是离线和预先建模,而且建模数据采集于某段时间,故用这些方法建立起来的热误差数学模型的稳健性显然不够,一般随着季节的变化难以长期正确地预报热误差。近年来,支持向量机是发展起来的一种专门研究小样本情况下的机器学习规律理论,被认为是针对小样本统计和预测学习的最佳理论[10]。支持向量机建立在Vapnik-Chervonenkis 维理论基础上,采用结构风险最小化原则,不仅结构简单,且有效解决了模型选择与欠学习、过学习、小样本、非线性、局部最优和维数灾难等问题,泛化能力大大提高[11-12]。本文对Leader way V-450 型数控加工中心进行热误差测量试验,采用模糊聚类与灰色关联度理论综合应用进行了温度敏感点选择,同时利用多元线性回归模型,分布滞后模型,支持向量回归机模型分别建立热误差补偿模型,并对多元回归模型分别采用最小二乘和最小一乘估计,通过比对各种模型的稳健性,从而为数控机床热误差补偿建模方法的选择提供了参考,具有实际的工程应用价值。
1 、热误差建模模型
1.1 多元线性回归模型
多元线性回归(Multiple linear regression, MLR)是一种用统计方法寻求多输入和单输出关系的模型。热误差的多元线性回归模型以多个关键温度敏感点测量的温度增量值为自变量,以热变形量为因变量,其通用表达式为

同时,采用最小一乘和最小二乘两种准则对线性回归模型进行估计计算。最小二乘法在方法上较为成熟,在理论上也较为完善,是一种常用的最优拟合方法,目前广泛应用于科学技术领域的许多实际问题中,在数控机床建模技术中也有很多的应用。而最小一乘法受异常值的影响较小,其稳健性比最小二乘法的要好,但最小一乘回归属于不可微问题,计算具有较大的难度。文中针对最小一乘的算法采用文献[13]的算法理论和Matlab 程序。最小二乘准则——残差平方和最小,即
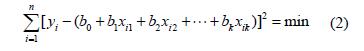

式中 IID ——标准正态分布的相互独立变量;
n ——最大滞后期;
a0 ——常数项;
u ——外生变量个数;
yt ——因变量;
βj,i ——系数;
xj,ti
——第j 个自变量的ti 期值。
对于滞后阶数n 的确定,由于试验测量数据量比较大,所以可以采用简单的权宜估计法。即取n=1,2, ,i,对不同的i 条件下经最小二乘拟合,当滞后变量的回归系数开始变得统计不显著,或其中有一个变量的系数改变符号时,i1 就是最终的滞后阶数。
1.3 支持向量回归机模型
统计学习理论是由VAPNIK[11]建立的一种专门研究有限样本情况下机器学习规律的理论,支持向量机是在这一理论基础上发展起来的一种新的分类和回归工具。支持向量机通过结构风险最小化原理来提高泛化能力,并能较好地解决小样本、非线性、高维数、局部极小点等实际问题,其已在模式识别、信号处理、函数逼近等领域应用。


引入拉格朗日函数,可得凸二次规划问题



2 、试验设计
2.1 试验方案
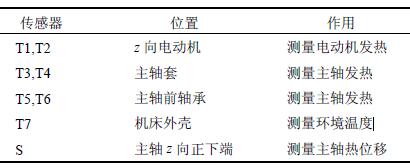
本文对Leader way V-450 数控加工中心主轴z向进行热误差测量试验,各传感器的安放位置及作用如表1 所示,温度传感器和电感测微仪具体分布位置如图1 所示。

图1 热误差测量试验
表1 传感器安放位置及作用
试验对数控加工中心在不同季节(不同环境温度)、不同主轴转速下进行了9 次热误差测量试验,测量的次数、转速及环境温度如表2 所示。
表2 试验批次的主轴转速和环境温度
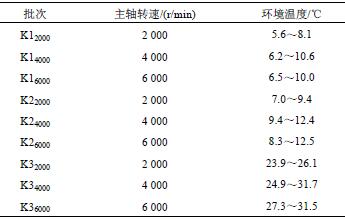
表2 中,Knm 含义是,第n 次测量的主轴转速在m 的试验数据。如K12000 表示第一次测量的主轴转速在2 000 r/min 的试验数据,K22000 表示不同环境温度下第二次测量的主轴转速在2 000 r/min 的试验数据,K32000 表示不同环境温度下第三次测量的主轴转速在2 000 r/min 的试验数据。
2.2 温度敏感点的筛选
为便于实际工程应用,针对温度传感器数目进行优化挑选,合理有效地筛选温度传感器有助于提高机床热误差建模精度。本文采用模糊聚类与回归关联度相结合的方法选择热误差关键敏感点,具体方法参考文献[15],最终选择T6 和T7 作为温度敏感点。
3 、建模模型的稳健性分析
稳健性是指在模型与实际对象存在一定差距时,模型依然具有较满意的模拟预测性能。本文利用多元线性回归的最小二乘、最小一乘估计模型,分布滞后模型以及支持向量回归机模型对K16000 数据分别建立预测模型,先进行各模型对本批数据的拟合精度进行分析,随后将该模型用于其他批次采样数据的预测,以判断模型的稳健性。同时,根据建模数据的来源批次特征,对各算法给予了稳健性分析。
3.1 不同算法的模型拟合精度分析



表3 各模型的拟合标准差 μm

由表3 可知,拟合精度SVR 最优,DL 其次,拟合精度最差的是MLR 最小一乘算法。
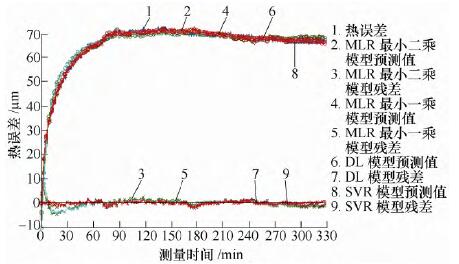
图2 对K16000 拟合效果
为比对各算法稳健性,利用各个模型建立的预测模型对其余批次数据按照同转速不同温度(环境温度变化范围较大)、同温度(环境温度变化较小)不同转速、不同温度(环境温度变化范围较大)不同转速三种类型进行数据预测,根据预测效果对各个补偿模型进行稳健性分析。
3.2 同转速不同环境温度分析
以K16000 数据建立的预测模型对K26000 数据进行预测精度分析,分析效果如图3 所示;再对K36000数据进行预测精度分析,分析效果如图4 所示。各个预测模型的预测标准差如表4 所示。
表4 各模型的预测标准差 μm
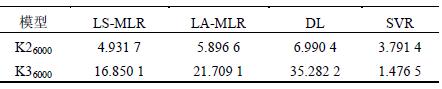
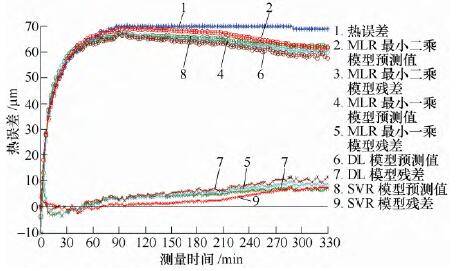
图3 对K26000 预测效果
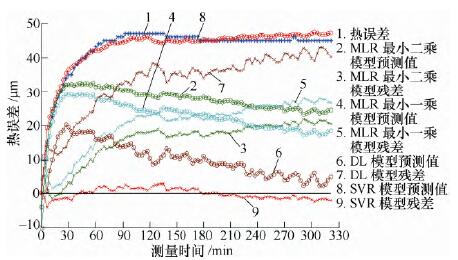
图4 对K36000 预测效果
通过分析比较可得,转速不变,环境温度增加较小时,各个预测模型的预测效果仍然保持较好,但是随着环境温度增加较大时,多元线性回归的最小二乘、最小一乘模型以及分布滞后模型的预测效果变差,其中多元线性回归的最小二乘算法相对较好,随后是最小一乘模型,预测效果最差的是分布滞后模型。除此之外,支持向量回归机模型仍能保
持很好的预测精度。
3.3 同温度不同转速分析
针对温度变化范围较小的不同转速测量数据,以K16000 数据建立的预测模型对K14000 和K12000 数据进行预测精度分析,根据分析数据结果来判断不同算法建立的模型的稳健性。先对K14000 数据进行分析,分析效果如图5 所示;然后分析K12000 数据,分析效果如图6 所示。各个预测模型的预测标准差如表5 所示。
表5 各模型的预测标准差 μm
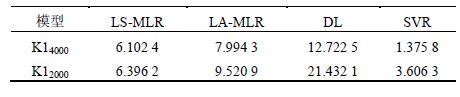
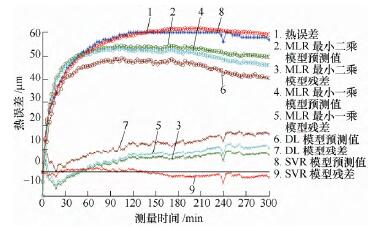
图5 对K14000 预测效果
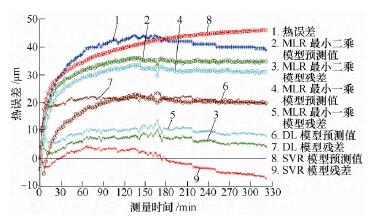
图6 对K12000 预测效果
通过分析比较可得,环境温度基本不变,转速逐渐降低时,最小二乘和最小一乘模型仍具有一定的预测精度,分布滞后模型预测效果越来越差,而支持向量回归机模型始终保持很好的预测精度。各算法稳定性优劣依次为支持向量回归机模型、最小二乘、最小一乘和分布滞后模型。
3.4 不同温度不同转速分析
针对环境温度变化时的不同转速测量数据,以K16000 数据建立的预测模型对K24000、K22000、K34000和K32000 数据进行预测精度分析,根据分析数据结果来判断不同算法建立的模型的稳健性。各个预测模型的预测标准差如表6 所示。
表6 各模型的预测标准差 μm
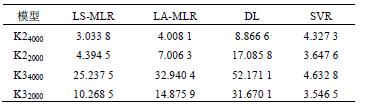
通过分析比较可得,环境温度变化幅度较小,转速逐渐降低时,最小二乘和支持向量回归机模型具有很好的预测精度,最小一乘模型的预测精度逐渐降低,分布滞后模型预测效果逐渐变差;环境温度变化幅度较大时(超过10 ℃),转速逐渐降低时,只有支持向量回归机模型仍保持较好的预测精度,其他的预测模型的预测效果很差。各算法稳定性优劣依次为支持向量回归机模型、最小二乘、最小一乘和分布滞后模型。
4 、结论
(1) 通过长期测量数控机床热误差和关键敏感点温度来获得多批次的试验数据,通过多种模型算法进行了预测建模,从机床主轴同转速不同环境温度、同环境温度不同转速、不同转速不同环境温度等三种情况对预测模型的精度与稳定性进行了分析。
(2) 从试验效果可知,分布滞后模型具有很好的拟合精度,但以一组采样数据建立的分布滞后模型其稳健性较差。仅以一组采样数据进行建模,最小一乘模型的稳健性并不优于最小二乘模型,反而略差。最小一乘法稳健性高于最小二乘法的说法,是基于对异常数据处理方面的优势,而数控机床热变形测量数据中出现异常数据的概率很小,使得该
法的优势并未得到体现,而且数控机床热误差数据样本量较大,最小一乘算法复杂,相对于最小二乘法,最小一乘法在数控机床热误差预测建模中的实际应用效果反而不如最小二乘法。
(3) 支持向量回归机模型拟合精度高,预测效果保持性好,稳健性强,该算法作为数控机床热误差补偿的建模算法具有工程应用基础。
投稿箱:
如果您有机床行业、企业相关新闻稿件发表,或进行资讯合作,欢迎联系本网编辑部, 邮箱:skjcsc@vip.sina.com
如果您有机床行业、企业相关新闻稿件发表,或进行资讯合作,欢迎联系本网编辑部, 邮箱:skjcsc@vip.sina.com
更多相关信息

